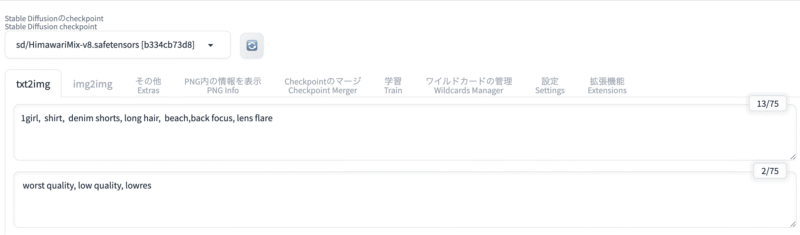
Stable Diffusionは、テキストから高品質な画像を自動生成できるAIです。
どうして画像を生成できるの?
「画像の特徴を学習したAIモデルが、ノイズから意味のある画像を復元するプロセス」を使っているからです。
まっさらなキャンバスに、目を閉じて少しずつ形を描きながら、
「これは猫っぽい」「これは夕焼けっぽい」と想像していく感じかな。
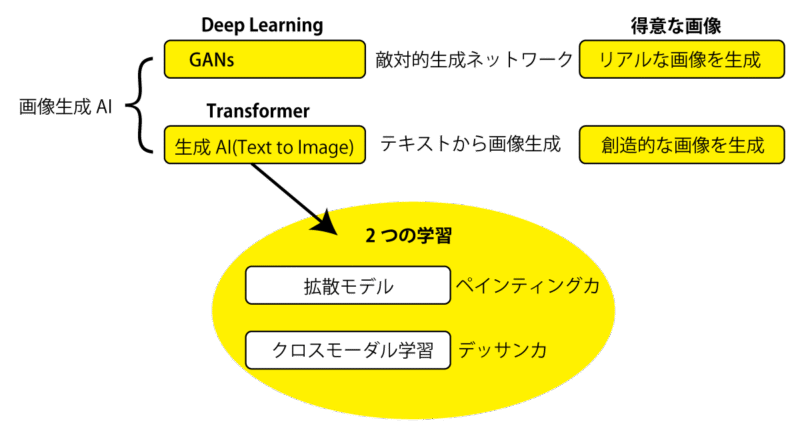
DeepLeaningとTrasformer
GANs(Generative Adversarial Networks、敵対的生成ネットワーク)
「生成器(Generator)」と「識別器(Discriminator)」を組み合わせて学習を行います。
現在の多くのAI言語モデルの基盤となっています。文章の特徴を抽出する「エンコーダ」と、特徴から新しい文章を生成する「デコーダ」に分かれています。
Transformer(トランスフォーマー)
Transformer(トランスフォーマー)は、2017年にGoogleの研究者たちによって発表された、自然言語処理(NLP)を中心に広く使われている深層学習モデルのアーキテクチャです。
自然言語処理(NLP)を中心に広く使われている深層学習モデルのアーキテクチャです。
2つの学習 拡散モデル+クロスモーダル学習
拡散モデル (Diffusion Model)
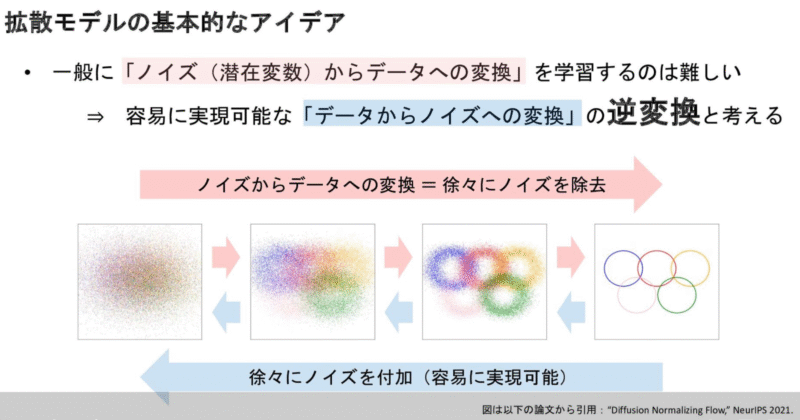
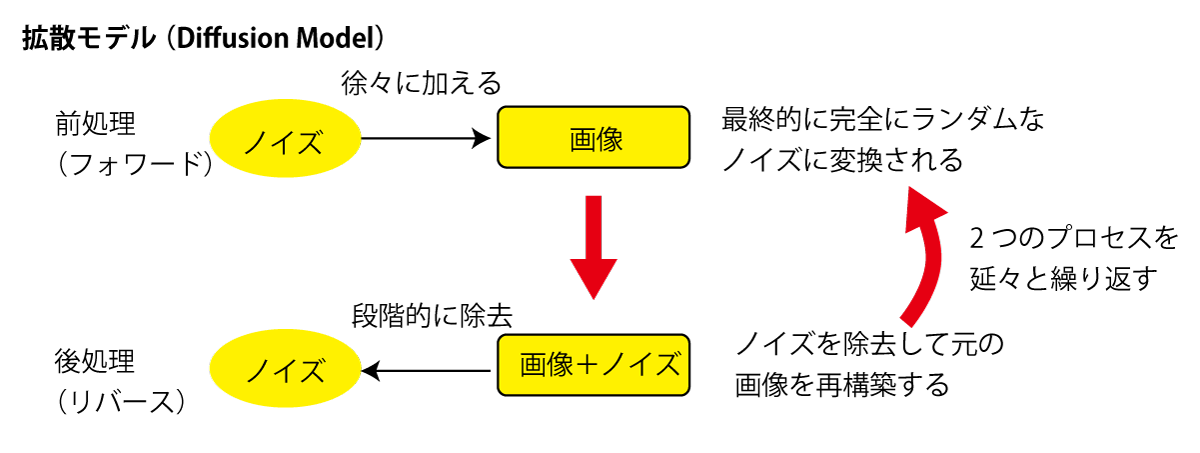
拡散モデルは、前処理と後処理の2つのプロセスを何度も繰り返すことで、絵を描く力を高めていく学習モデルです。
この学習は、絵を描く基礎となるペインティング力(色彩感覚、筆遣い、素材の理解、表現力など)を伸ばすのに役立ちます。
前処理(フォワードプロセス)
まず、元の画像に少しずつノイズを加えていきます。ノイズを加え続けると、最終的には完全にランダムなノイズ(ぐちゃぐちゃな画像)になります。このプロセスを何度も繰り返すことで、画像の変化やパターンのバリエーションを学びます。つまり、ノイズを加えることで、さまざまなパターンの画像を経験するわけです。
後処理(リバースプロセス)
次に、ノイズを段階的に取り除いて、元の画像に近づけていきます。最初のうちは、まだノイズが多くて元の画像の特徴がうまく伝わりませんが、徐々にノイズを減らすことで、元の画像に近づいていきます。このとき、元画像と今の画像の違い(損失関数)を見ながら調整します。こうして、ノイズを効率よく除去する力がアップしていきます。このプロセスも何度も繰り返すことで、ペインティング力(こんなふうに塗るとこうなる)が強化されます。
クロスモーダル学習
「モーダル」とは、画像・音声・テキストなど、データの種類のことを指します。クロスモーダル学習では、たとえば「画像とその説明文」や「音声とテキスト」など、複数のモーダルを同時に使ってAIを学習させます。この方法を使うと、テキストと画像をペアで学ぶことができ、たとえばデッサン力(デザインの感覚や構図、ストーリー性など)を身につけることも可能です。さらに、与えられたテキストから新しい絵を生み出す力も持っています。こうした仕組みが「クロスモーダル学習」と呼ばれ、AIが次に来る単語を予測したり、画像を生成したりできる理由になっています。
- どんなことができる?
画像を見て説明文を自動生成する(画像→テキスト) - 音声を聞いて内容を文字に起こす(音声→テキスト)
- テキストから画像を生成する(テキスト→画像)
タグ方式とCLIP方式
タグ方式
- ・シンプルで直感的。タグを並べるだけでOK。「タグ」(例:cat, sunset, 1girl など)
・イラストやアニメ系の画像生成に強い。イラスト系AI(NovelAIやにじジャーニーなど)で使われています。
細かいニュアンスや複雑な指示は苦手です。
CLIP方式
- ・普通の英語の文章で細かい指示ができる。
・複雑なシーンや雰囲気も伝えやすい。
英語力が多少必要です。
ポジティブプロンプトとネガティブプロンプト(ネガプロ)
ポジティブプロンプト
- ・「こういう画像を作ってほしい」とAIに伝えるための指示です。
・画像に入れたい要素や雰囲気を具体的に書きます。
例:「青い空の下で笑っている女の子」「cat, sunset, beautiful」
ネガティブプロンプト
- ・「こういう要素は入れないでほしい」とAIに伝えるための指示です。
・画像に入れたくない特徴や避けたい表現を指定します。
例:「ぼやけていない」「手が6本ではない」「blurry, extra fingers, low quality」
よく使われるネガティブプロンプト一覧
blurry(ぼやけている)
low quality(低品質)
bad anatomy(体のバランスが変)
bad hands(手の形が変)
extra fingers(指が多い)
missing fingers(指が足りない)
deformed(体の一部が歪んでいる)
mutated(突然変異のような見た目)
watermark(透かし・ロゴが入っている)
text(画像内に文字が入っている)
cropped(画像が途中で切れている)
worst quality(最悪の品質)
jpeg artifacts(画像の圧縮ノイズ)
signature(サインが入っている)
long neck(首が長すぎる)
bad proportions(体の比率が変)
Textual Inversion
Textual Inversionは、「自分だけのキーワードで、特定の特徴をAIに覚えさせる」ための方法です。これを使うと、より自由で個性的な画像生成ができるようになります。
WebUI
Stable Diffusion WebUIは、「AIに絵を描いてもらう」ための便利なウェブアプリです。
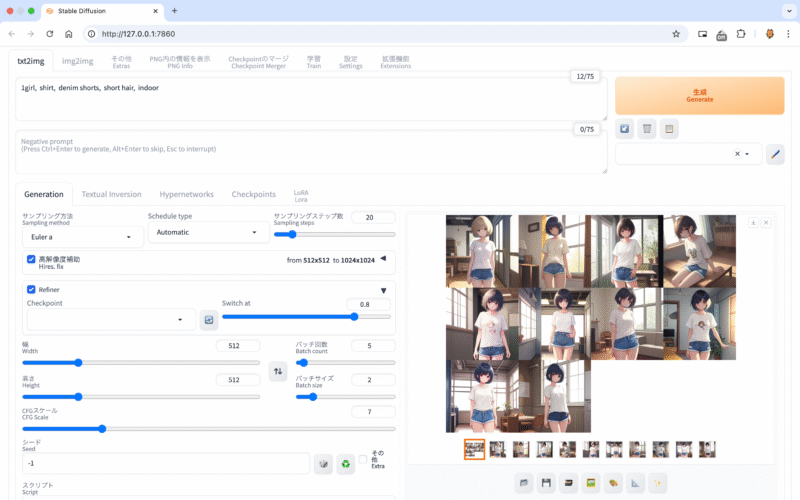



テキストで「こんな画像がほしい」と指示を出すと、AIがその内容に合った画像を自動で作成してくれます。




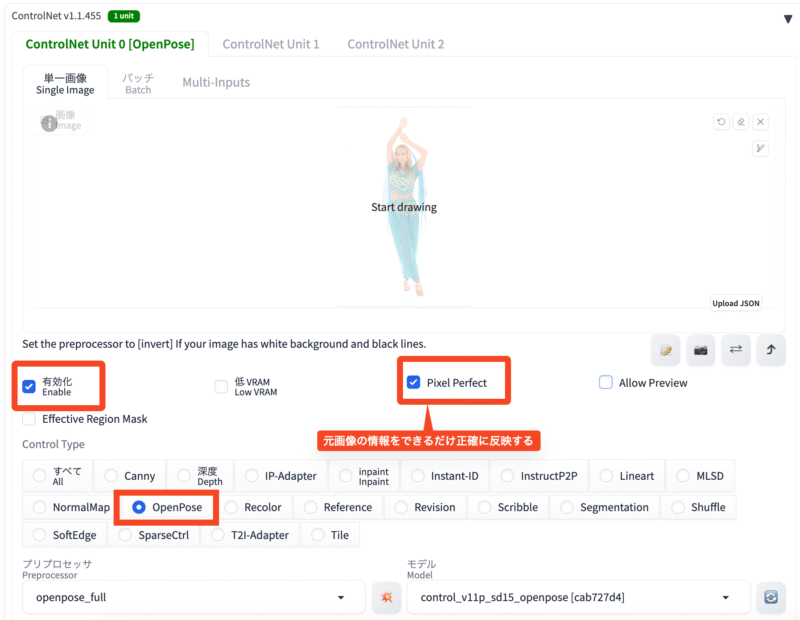
ControlNet openpose
OpenPose=人のポーズ(骨格)を検出するAI技術
ControlNetのOpenPoseは、「人のポーズを細かく指定して、その通りに画像を作る」機能です。まるで「ポーズの設計図」をAIに渡して、その通りに絵を描いてもらうようなイメージです。これを使うと、より具体的で意図した通りの画像を作りやすくなります!
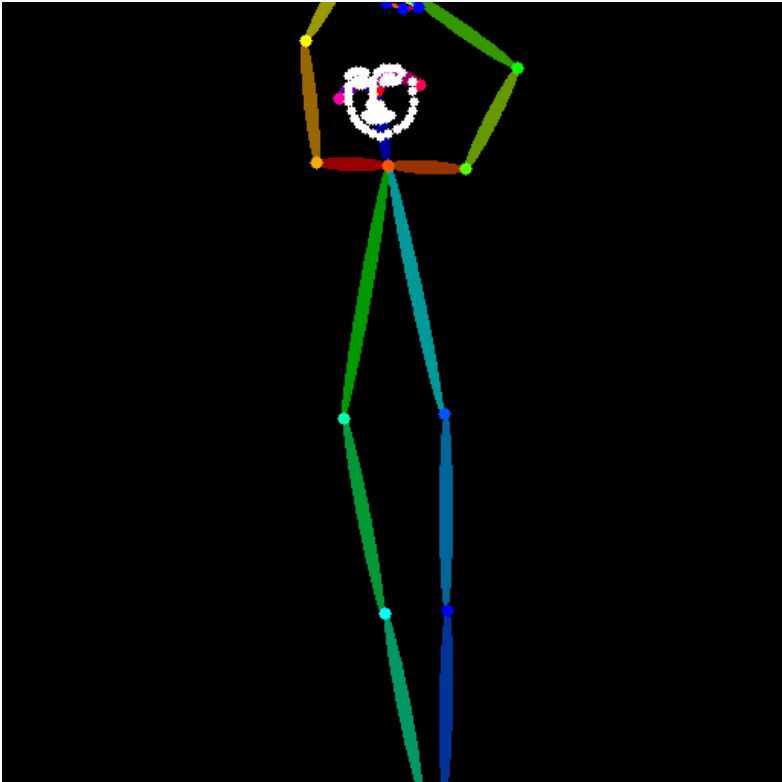
▲姿勢検出画像

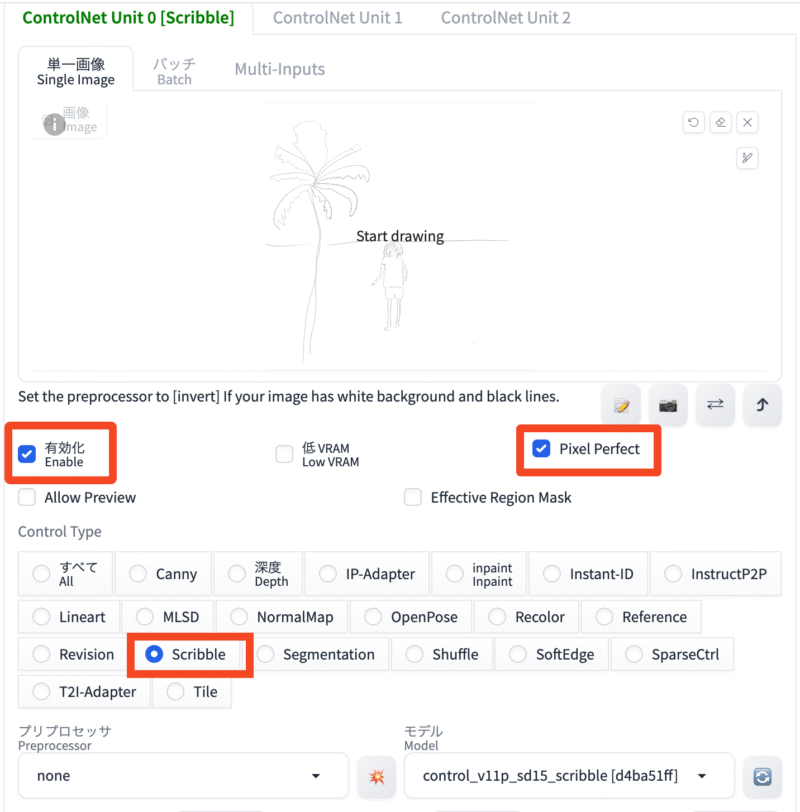
ControlNet Scribble
ラフなスケッチや線画をもとにして、完成度の高い画像を生成するための機能です。